Platform ·Part 2 · May 7, 2026
KubeTrader: Data Platform
A visual tour of the running platform: distribution, storage & serving, orchestration, research, and delivery.
Part 1 covered the why and the ingest path; this part walks the rest of the system, mostly through short clips and diagrams.
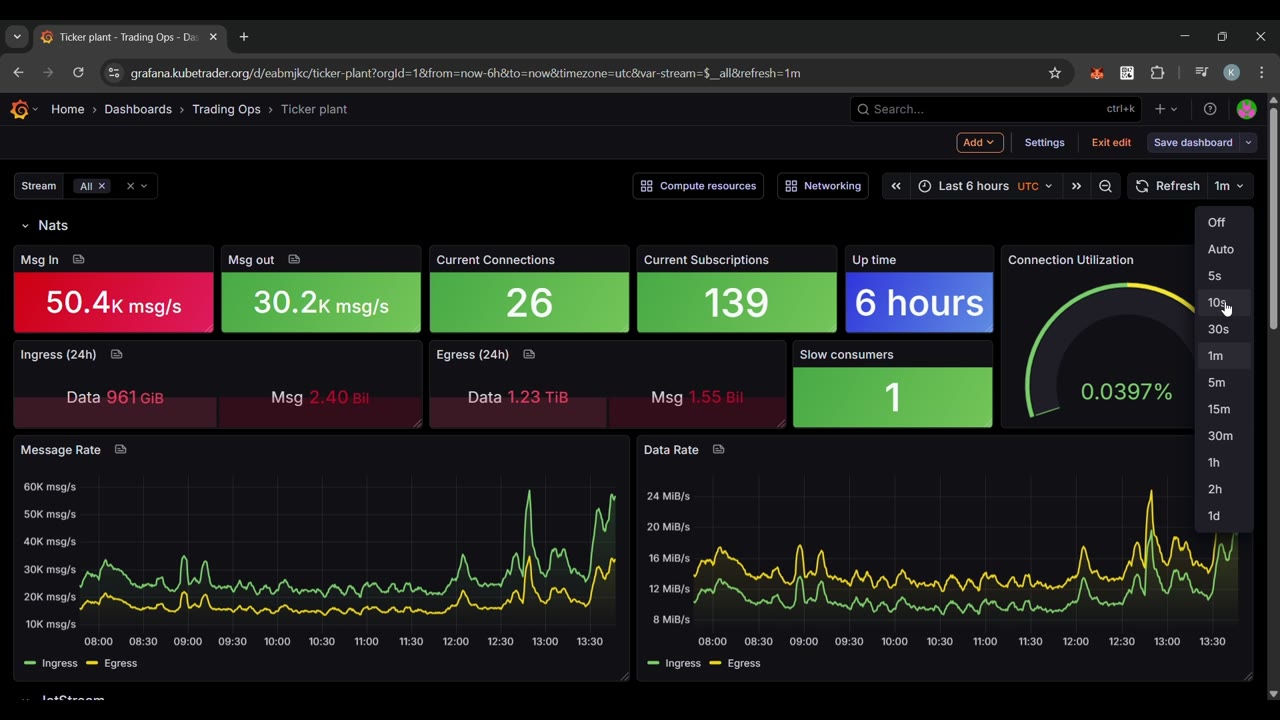
3. Distribution — NATS / JetStream
- Core NATS for messaging on the hot path.
- Test environments mirror only the data they need via leaf nodes.
- The data warehouse pulls at its own pace via JetStream.
4. Storage & Serving
Storage
- Tiered ClickHouse cluster backed by S3 as the OLAP store.
- Idempotency via ReplacingMergeTree.
- Ingest straight off the NATS engine (JetStream pull-consumer configuration).
- Aurora Serverless v2 as unified storage for internal app state.
- Migrations via Flyway.
Serving
- ClickHouse client in Grafana (Business Charts plugin).
A couple of examples of the serving surface in use:
- Basis analytics dashboards
- Order drill-down
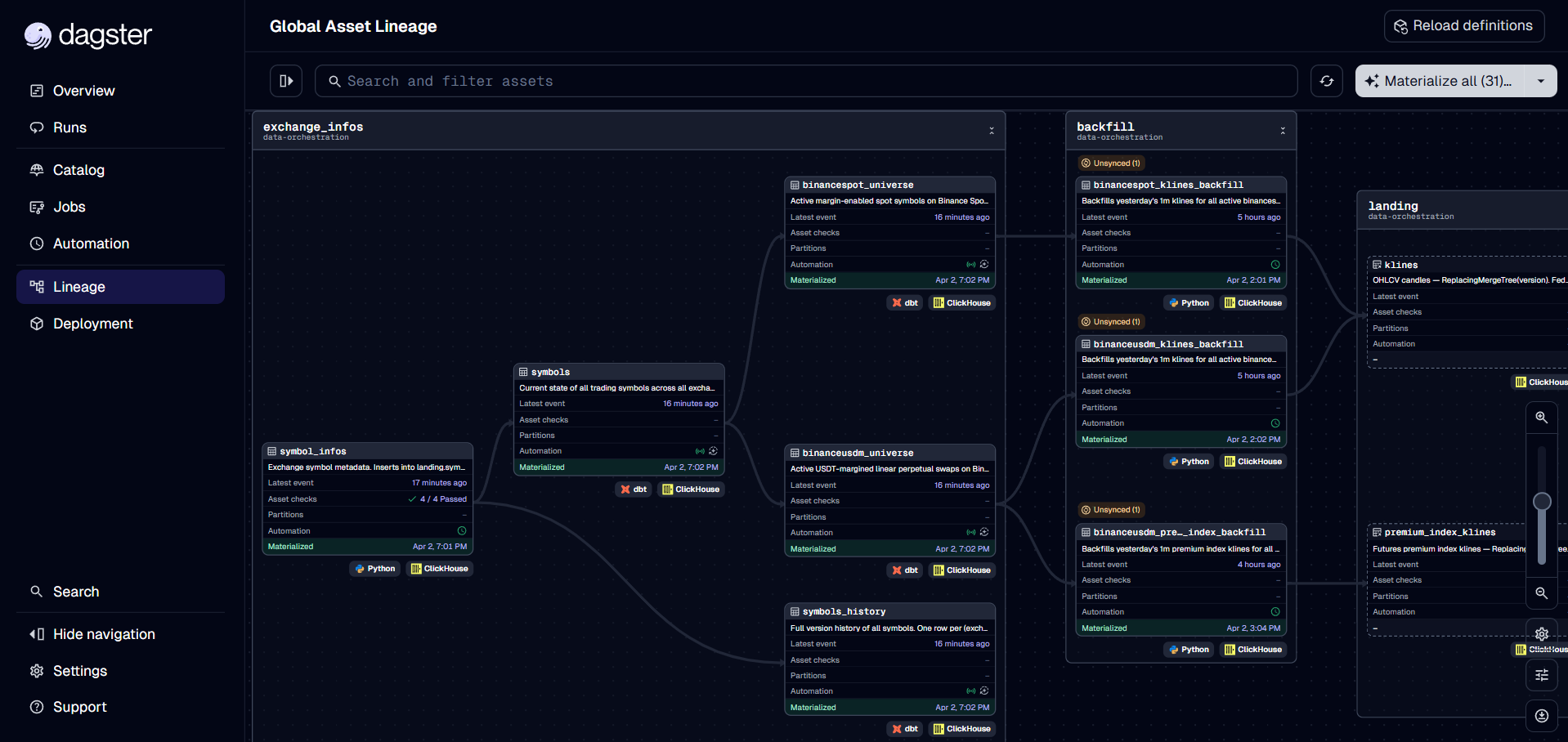
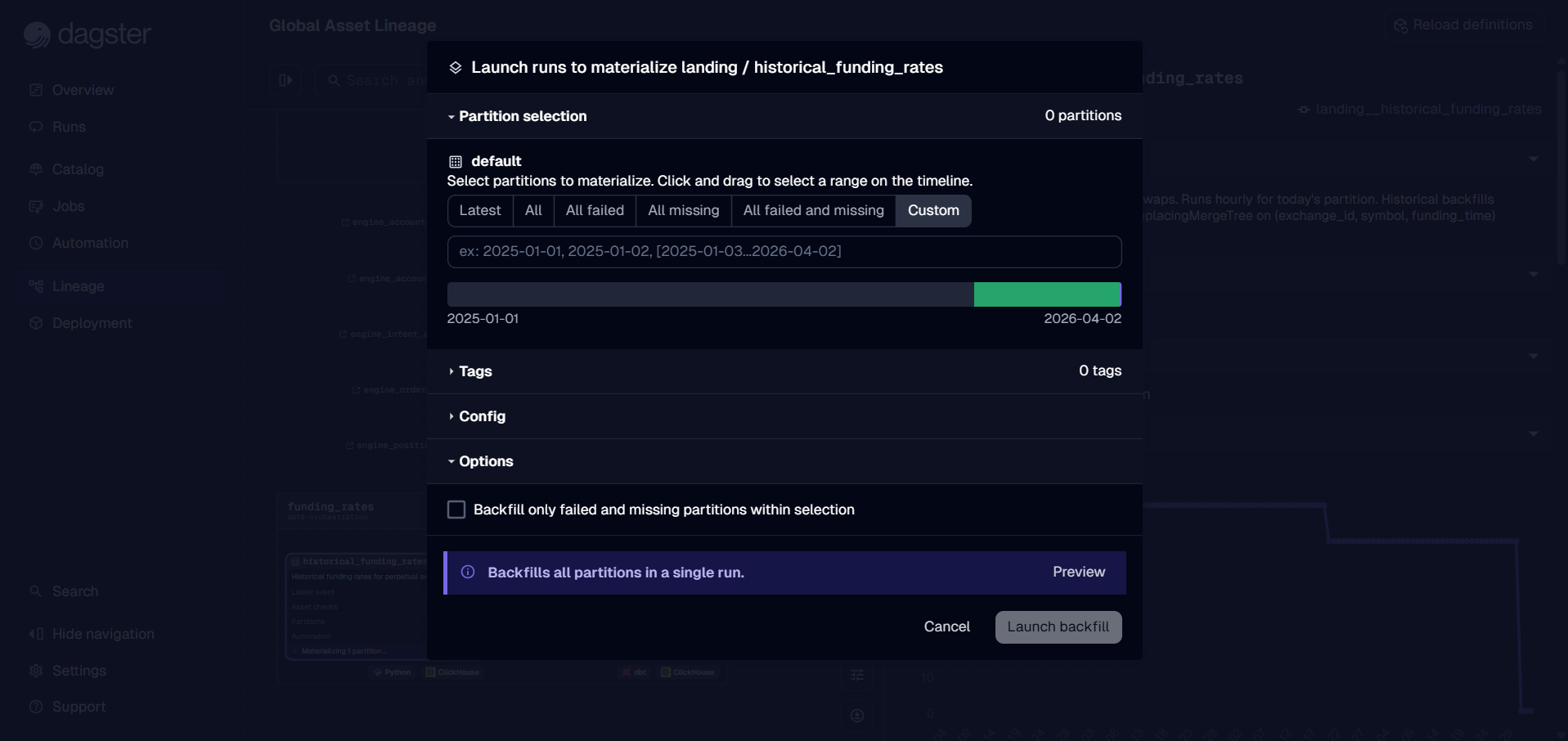
5. Orchestration — Dagster
- Backfill operations.
- SCD2 data collection & insertion.
- Triggers dbt data transformations.
- Visual lineage.
- Backtest & reporting.
The example clips walk a Dagster tour, then backfill jobs that trigger spot-node provisioning and schedule onto it.
6. Research — On-Demand Compute
On-demand provisioned compute environments (S / M / L), launched via Jupyter Enterprise Gateway, running as remote kernels on Kubernetes, with cluster capacity dynamically scaled by Karpenter, and controlled access to ClickHouse and AWS services (S3, Bedrock).
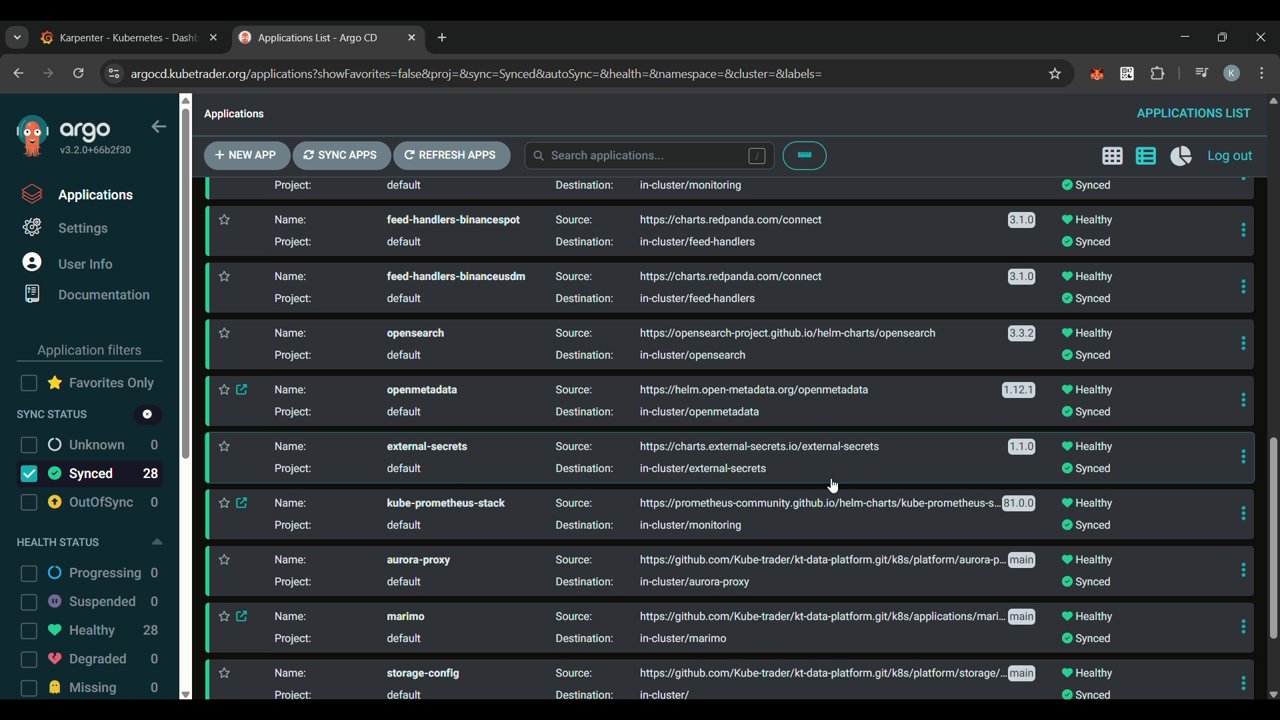
7. Delivery — GitOps CI/CD
Two main delivery paths:
- Internal-built services — continuous delivery without babysitting tags, via Argo Image Updater.
- External services — manifests picked up directly by Argo CD.